Data Normalization
- 데이터베이스를 조금 더 조직적이고 일관화 된 방법으로 디자인하려는 방법
- 데이터베이스의 정합성을 쉽게 유지하고 레코드들을 수정/적재/삭제를 용이하게 함
- Normalization에 사용되는 개념
- Primary Key
- Composite Key
- Foreign Key
1NF (Frist Normal Form) - 중복된 키를 제거하고 atomicity 한 것이 목표
- 한 셀에는 하나의 값만 있어야 함 (atomicity)
- Primary 키가 있어야 함
- 중복된 키나 레코드 값이 없어야 함
2NF (Second Normal Form)
- 1NF를 만족해야 함
- 다음으로 Primary 키를 중심으로 의존결과를 알 수 있어야 함
- 부분적인 의존도가 없어야 함
- 즉, 모든 부가 속성들을 Primary Key를 가지고 찾을 수 있어야 함
- 모든 키는 Primary Key를 기준으로 종속되어야 함
3NF (Third Normal Form)
- 2NF를 만족해야 함
- 전이적 부분 종속성을 없애야 함
Slowly Changing Dimensions
- DW나 DL에서는 모든 테이블들의 히스토리를 유지하는 것이 중요
- 보통 두 개의 timestamp 필드를 갖는 것이 좋음
- created_at (생성시간으로 한 번 만들어지면 고정)
- updated_at (꼭 필요 마지막 수정 시간을 나타냄)
- 보통 두 개의 timestamp 필드를 갖는 것이 좋음
- 이 경우 컬럼의 성격에 따라 어떻게 유지할지 방법이 달라짐
- SCD Type 0
- SCD Type 1
- SCD Type 2
- SCD Type 3
- SCD Type 4
SCD Type 0
- 한 번 쓰고 나면 바꿀 이유가 없는 경우들
- 한 번 정해지면 갱신되지 않고 고정되는 필드들
- Ex_) 고객 테이블이라면 회원 등록일, 제품 첫 구매일
SCD Type 1
- 데이터가 새로 생기면 덮어쓰면 되는 컬럼들
- 처음 레코드 생성시에는 존재하지 않았지만 나중에 생기면서 채우는 경우
- Ex_) 고객 테이블이라면 연간소득 필드
SCD Type 2
- 특정 entity에 대한 데이터가 새로운 레코드로 추가되어야 하는 경우
- Ex_) 고객 테이블에서 고객의 등급 변화
- standard -> vip 변경 시
- 변경되는 시간도 같이 추가되어야 함
SCD Type 3
- SCD Type 2의 대안으로 특정 entity 데이터가 새로운 컬럼으로 추가되는 경우
- Ex_) 고객 테이블에서 tier라는 컬럼의 값이 standard -> vip로 변하는 경우
- previous_tier 라는 컬럼 생성
- 변경 시간도 별도 컬럼으로 존재해야 함
SCD Type 4
- 특정 entity에 대한 데이터를 새로운 Dimension 테이블에 저장하는 경우
- SCD Type 2의 변종
- Ex_) 별도의 테이블로 저장하고 이 경우 아예 일반화 할 수도 있음
DBT (Data Build Tool)
dbt란?
- Data Build Tool
- 다양한 데이터 웨어하우스를 지원
- 클라우드 버전도 존재
dbt 구성 컴포넌트
- 데이터 모델 (models)
- 테이블들을 몇 개의 티어로 관리
- 일종의 CTAS (SELECT 문들), Lineage 트래킹
- Table, View, CTE 등등
- 테이블들을 몇 개의 티어로 관리
- 데이터 품질 검증 (tests)
- 스냅샷 (snapshot)
Fact 테이블과 Dimension 테이블
- Fact 테이블 - 분석의 초점이 되는 양적 정보를 포함하는 중앙 테이브
- 일반적으로 매출 수익, 판매량, 이익과 같은 측정 항목 포함. 비즈니스 결정에 사용
- Fact 테이블은 일반적으로 외래 키를 통해 여러 Dimension 테이블과 연결됨
- 보통 Fact 테이블의 크기가 Dimension 테이블보다 큼
- Dimension 테이블 - Fact 테이블에 대한 상세 정보를 제공하는 테이블
- 고객, 제품과 같은 테이블로 Fact 테이블에 대한 상세 정보 제공
- Fact 테이블의 데이터에 맥락을 제공하여 다양한 방식으로 분석 가능하게 해줌
- Dimension 테이블은 primary key를 가지며, fact 테이블에서 참조 (foreign key)
- 보통 Dimension 테이블의 크기가 훨씬 작음
Model (Input)
- ELT 테이블을 만듦에 있어 기본이 되는 빌딩블록
- 테이블이나 뷰나 CTE의 형태로 존재
- 입력, 중간, 최종 테이블을 정의하는 곳
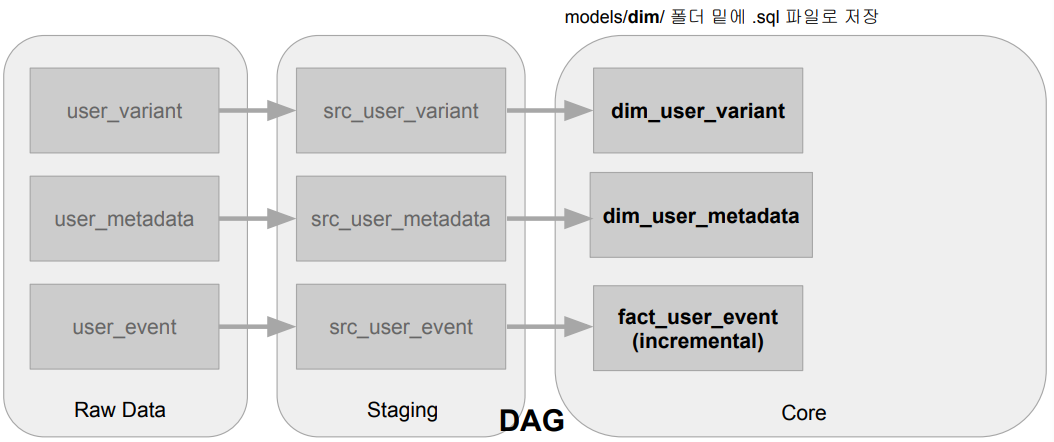
- 모델의 tier (raw, staging, core ....)
- raw -> staging (src) -> core
- View 란?
- SELECT 결과를 기반으로 만들어진 가상의 테이블
- 기존 테이블의 일부 혹은 여러 테이블들을 조인한 결과를 제공
- CREATE VIEW 이름 AS SELECT .... - VIew의 장점
- 데이터의 추상화 : 사용자는 View를 통해 필요 데이터에 직접 접근. 원본 데이터를 알 필요가 없음
- 데이터의 보안 : View를 통해 사용자에게 필요한 데이터만 제공. 원본 데이터 접근 불필요
- 복잡한 쿼리의 간소화 : SQL(View)를 사용하면 복잡한 쿼리를 단순화 - View의 단점
- 매번 쿼리가 실행되므로 시간이 걸릴 수 있음
- 원본 데이터의 변경을 모르면 실행이 실패
- SELECT 결과를 기반으로 만들어진 가상의 테이블
- CTE (Common Table Expression)
- Model의 구성 요소
- Input
- 입력 (raw)과 중간 (staging, src) 데이터 정의
- raw는 CTE로 정의
- staging은 View로 정의 - Output
- 최종 (core) 데이터의 정의
- core는 Table로 정의 - Input, Output 모두 models 폴더 및에 sql 파일로 존재
- 기본적으로 SELECT + Jinja 템플릿과 매크로
- 다른 테이블들을 사용 가능 (reference) (-> 이를 통해 리니지 파악)
- Input

Materialization (Output)
- 입력 데이터 (테이블)들을 연결해서 새로운 데이터 (테이블)를 생성하는 것
- 일반적으로 여기서 추가 transformation이나 데이터 클린업을 진행
- 4가지의 내장 materialization이 제공됨
- 파일이나 프로젝트 레벨에서 가능
- dbt run을 기타 파라미터를 가지고 실행
4가지 materialization 종류
- View
- 데이터를 자주 사용하지 않는 경우
- Table
- 데이터를 반복해서 자주 사용하는 경우
- Incremental (Table Appends)
- Fact 테이블
- 과거 레코드를 수정할 필요가 없는 경우
- Ephemeral (CTE)
- 하나의 SELECT에서 자주 사용되는 데이터를 모듈화하는데 사용

728x90
'ssung_데이터 엔지니어링 > 11주차_Airflow 고급' 카테고리의 다른 글
| Airflow 고급_(5) (0) | 2024.01.05 |
|---|---|
| Airflow 고급_(3) (0) | 2024.01.03 |
| Airflow 고급_(1), (2) (2) | 2024.01.03 |