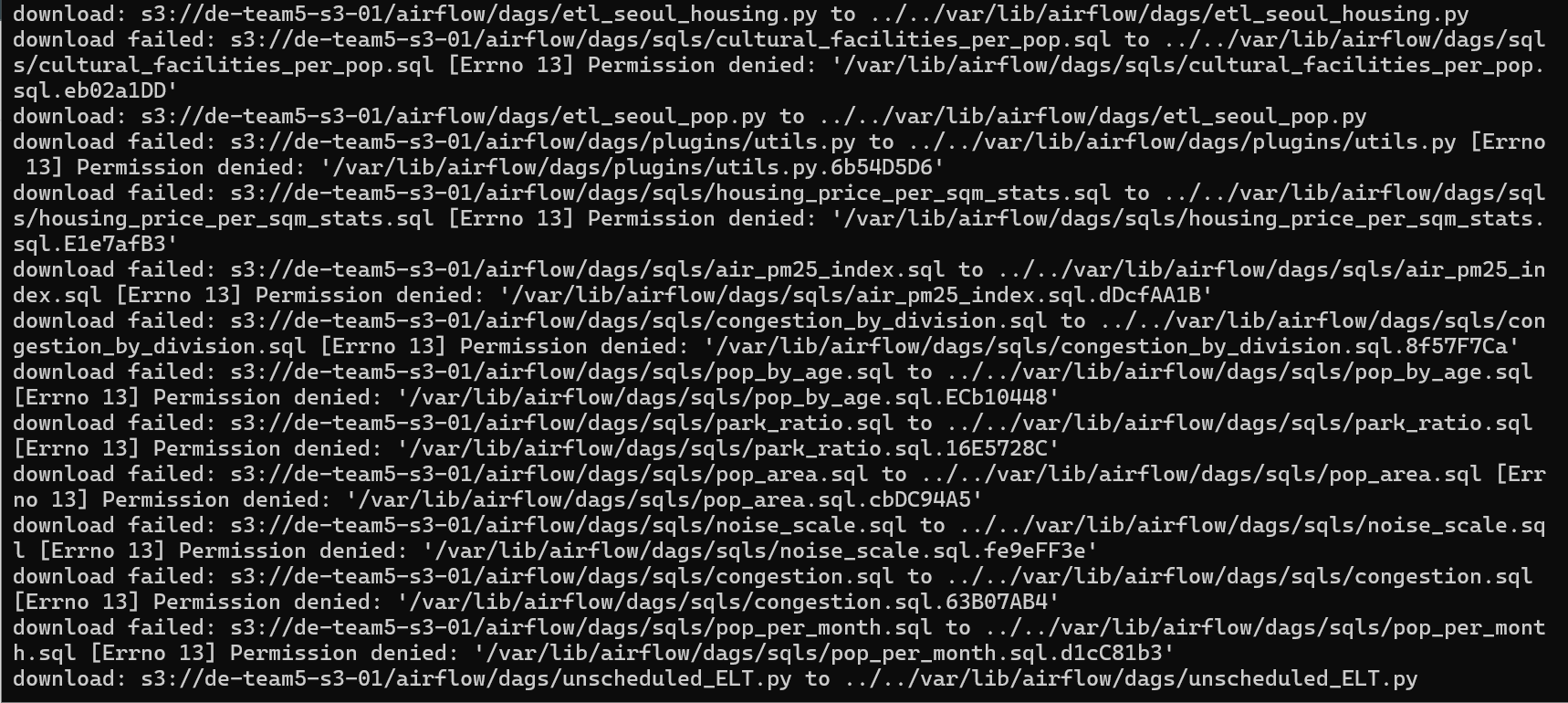
AWS Cli Sync 권한 문제 문제 : ubuntu 환경에서 aws cli를 통해 sync를 진행했을 때 해당 폴더에 sync를 진행하고자 했을 때 '[Errno 13] Permission denied' 에러가 발생함 원인 : ubuntu 환경에서 폴더 및 파일 권한에 대한 문제로 발생하는 이슈 해결 : ubuntu 환경에서 해당 폴더에 모든 권한을 주는 명령어 실행 sudo chmod 777 '파일 경로' 정상적으로 sync 된 것을 확인