문제 상황 발생...
EDA를 위해 전처리 했던 데이터가 EDA를 진행하면서 전처리가 잘못 되었다는 것을 알게 되었다..
원인은 제주 지역 위·경도의 좌표가 잘못 되어있었던 것...
구글맵에서 직접 위·경도 좌표를 찍어가며 다시 좌표를 수정하여 전처리 데이터를 추출
그랬더니.. 기존 CSV 파일의 개수에 비해 2배가 되는 파일이 나옴.
역시.. 깨달은 교훈 - 직접 확인하기 전까지는 의심하고 또 의심해라 라는 말이 맞는 것 같다..
그렇다면 이제 전처리 작업을 위해 가공한 데이터에서 어떠한 데이터를 뽑아낼지 생각해보고 코드로 옮겨보자

- 발생 시간을 활용해 '월' 데이터를 추출하고 column에 추가
df['월'] = df['돌발일시'].str.slice(5, 7).astype(int)
간단하게 '돌발일시' 컬럼을 문자로 바꾸고 슬라이싱해서 다시 숫자형으로 바꿔 추출 완료

- '월' 데이터를 활용해서 '계절' column을 추가
제주도라는 위치적 특성 상 어떤 계절에 돌발 상황이 가장 많이 일어나는지를 쉽게 확인하기 위해 데이터 추출
df['계절'] = (df['월'] // 3) % 4
season_mapping = {0 : '겨울', 1 : '봄', 2 : '여름', 3 : '가을'}
df['계절'] = df['계절'].map(season_mapping)
우선, '월' 데이터를 3으로 나눈 뒤 나온 몫을 가지고 다시 4로 나누어 나온 나머지를
딕셔너리 형태로 저장된 계절 데이터에 맞게 맵핑 시켜주면 계절 데이터 추출 완료!
- '돌발시작일시' 데이터를 활용해 '시간대' column을 추가
돌발 상황이 발생한 시간대 (오전, 오후, 저녁, 새벽)를 파악해보자
df['상황 발생 시간대'] = df['돌발시작일시'].str.slice(11, 13)
df['상황 발생 시간대'] = df['상황 발생 시간대'].str.replace(':', '')
df['상황 발생 시간대'] = df['상황 발생 시간대'].astype(int)
df['상황 발생 시간대'] = (df['상황 발생 시간대'] // 6) % 4
time_zone_mapping = {0 : '새벽', 1 : '오전', 2 : '오후', 3 : '저녁'}
df['상황 발생 시간대'] = df['상황 발생 시간대'].map(time_zone_mapping)
'시간대' 를 도출하는 방법은 위에서 진행했던 계절 데이터와 방법이 거의 같다고 보면 된다!
하지만, 이를 위한 조그마한 전처리가 필요했는데
위의 코드에서 첫 번째, 두 번째 코드를
# 적용된 코드
df['상황 발생 시간대'] = df['돌발시작일시'].str.slice(11, 13)
df['상황 발생 시간대'] = df['상황 발생 시간대'].str.replace(':', '')
# 적용하고 싶었던 코드
df['상황 발생 시간대'] = df['돌발시작일시'].str.slice(11, 13).replace(':', '')
위와 같이 한 줄로 작성하고 싶었는데, 무슨 이유였는지 한 번에 적용이 불가능했다..
(ex_ '9:'와 같이 슬라이싱 되는 데이터를 한 번에 대체하여 간단화 하고 싶었는데, 한 줄로 적으면 대체가 안됨)
원인이 무엇이었을까.. 일단은 데이터가 추출 되었으니 우선은! 다음 단계로
- '돌발내용'에서 도로명을 추출
돌발 내용에서 도로명을 추출해보자
# 함수 정의
def extract_road_name(text):
road_name = text.split()
if '>' in road_name[0]
return road_name[1]
return road_name[0]
def road_name(df):
df['돌발내용'] = df['돌발내용'].astype(str)
df['도로명'] = df['돌발내용'].apply(extract_road_name)
return df
함수를 하나의 함수로 합쳐서 작성할 수 있었지만
함수 안에 또 다른 함수가 있으면 보기가 불편한 것 같았다. 개인적으로..
(아직 코딩 실력이 부족해서 그럴 가능성이 매우 큼)
또한, 함수를 두 개로 나누었을 때가 시각적으로 알아보기 편했음
extract_road_name 에서 내용을 공백으로 나눈 뒤 '>' 특수 문자를 하나만 적용한 이유는
해당 특수문자 밖에 없었기 때문... 여러 개의 특수 문자가 있는데, '>' 일때만 한 것은 아무래도..ㅡㅡ
개선이 필요한 부분이다!
- '도로명' column을 활용해 '제주시', '서귀포시'를 구분해보자
가장 까다로웠던 부분이었다고 말할 수 있을 것 같다
지도에서 보면 제주도의 모양? 위치?가 정직하게 있는 것이 아니라
약간 대각선 마냥 살짝 기울어져 있는데, 여기서 또
'제주시'와 '서귀포시' 가 적나라하게, 아주 격하게 대각으로 나뉘어져 있다..
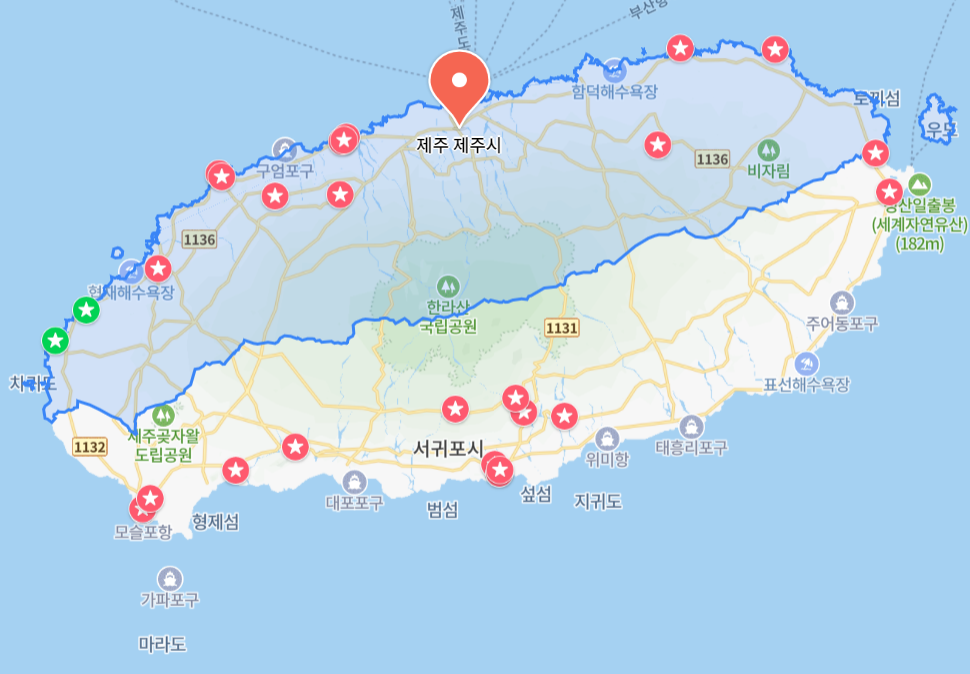
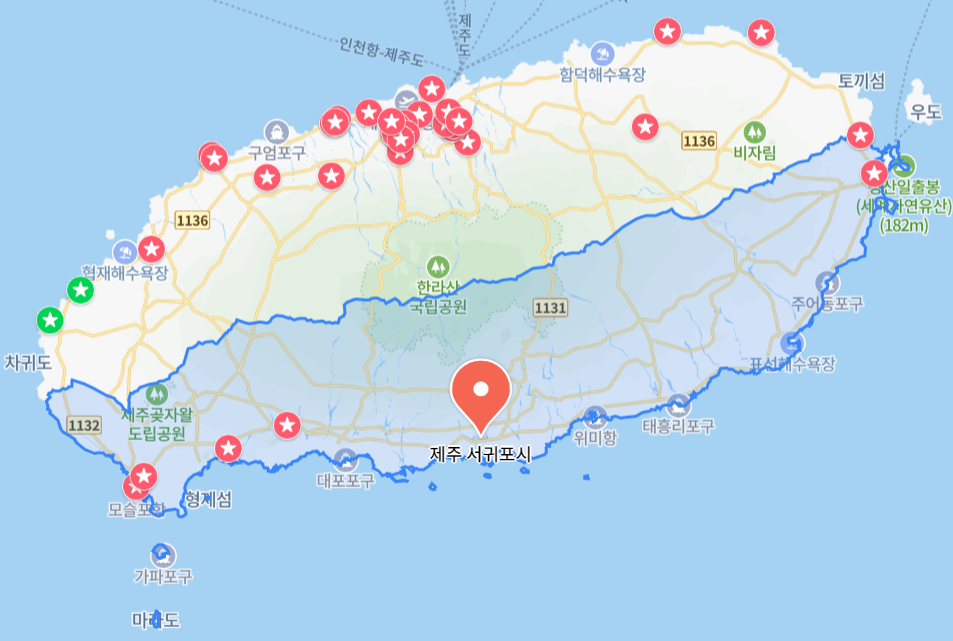
한 마디로 좌표를 통해서 정확하게 할 수도 있겠지만! 상당히 작업이 오래 걸릴 것 같고
힘들 것 같다는 결론이 나옴..
결국 한참을 생각하다.. 도로명 주소를 활용한 방법을 생각해냄!
제주도는 두 개의 시로 나뉘어 있으니 당연히 시청도 2개이고 관리하는 도로도 다를 것이니!
각 시 별로 도로명 데이터를 가지고 발생한 구역을 나누기 성공!
코드로 살펴보자
import chardet
import os
# 인코딩 형식이 다름으로 인코딩 파악 함수 정의
def detect_encoding(file_path):
with open(file_path, 'rb') as f:
raw_data = f.read()
result = chardet.detect(raw_data)
return result['encoding']
folder_path = r'C:jupyter~~~\~~~\~~~'
for file name in os.listdir(folder_path):
file_path = os.path.join(folder_path, filename)
print(f"Processing file : {file_path}")
# 파일 인코딩 확인
encoding = detect_encoding(file_path)
print(encoding)# 제주시, 서귀포시 도로명 데이터를 리스트에 저장
# 해당 코드에서는 생략되었지만
# 아래의 코드는 미리 csv 파일을 불러와 jupyter에 데이터를 저장해놓은 상태
jeju = df_jeju['도로명']
jeju = jeju.values
jeju = jeju.tolist()
seogwipo = df_seogwipo['도로명']
seogwipo = seogwipo.values
seogwipo = seogwipo.tolist()
def seperate_jeju(df, jeju, seogwipo):
df['지역구분'] = None
for idx, row in df.iterrows():
if row['도로명'] in jeju:
df.at[idx, '지역구분'] = '제주시'
elif row['도로명'] in seogwipo:
df.at[idx, '지역구분'] = '서귀포시'
else:
df.at[idx, '지역구분'] = row['도로명']
return df
위의 코드에서 보면 jeju 리스트와 seogwipo 리스트를 정의해
도로명 column을 읽으면서 도로명이 jeju 리스트에 있으면 제주시
seogwipo 리스트에 있으면 서귀포시
없으면 그냥 '도로명'을 저장하였는데, 없으면 도로명을 저장한 이유는
전처리 데이터가 3년 전 데이터로써, 3년동안 도로명이 개정되었고,
일부 몇몇 도로가 제주시와 서귀포시를 잇는 도로가 있기 때문이었다. (ex_11XX 도로)
'ssung_인턴일지' 카테고리의 다른 글
| 14일차_pandas 주요 기능 복습 (4) | 2024.07.20 |
|---|---|
| 10일차_Image stitching (0) | 2024.07.14 |
| 9일차_EDA란? (1) | 2024.07.14 |
| 8일차_Data Preprocessing(3) (0) | 2024.07.11 |
| 7일차_Data Preprocessing(2) (0) | 2024.07.08 |