Elasticsearch
- 기본적으로 모든 데이터를 색인하여 저장하고 검색, 집계 등을 수행하며 결과를 클라이언트 또는 다른 프로그램으로 전달
- 기존 관계형 DB 시스템에서 다루기 어려운 전문검색(Full Text Search) 기능과 점수 기반의 다양한 정확도 알고리즘, 실시간 분석 등의 구현이 가능
- 오픈소스
- Apche 2.0 라이센스로 배포중
- 실시간 분석
- Elasticsearch 클러스터가 실행되고 있는 동안에는 계속해서 데이터가 입력되고(검색엔진에서는 indexing 이라 표현), 그와 동시에 실시간에 가까운(near real-time) 속도로 색인된 데이터의 검색, 집계가 가능
- 전문 (full text) 검색 엔진
- 루씬 = 역파일 색인(inverted file index) 구조로 데이터 저장
- 루씬을 사용하는 Elasticsearch도 마찬가지로 역파일 색인 구조로 저장 후 가공된 텍스트 검색 하는데 이것을 전문검색 엔진이라고 함
- JSON 문서 기반의 역파일 색인 구조로 데이터 저장, 간결하고 다루기 편해 문서 가공 또는 클라이언트 프로그램과 연동에 용이
- key-value 형식이 아닌 문서 기반이므로 복합적인 문서를 있는 그대로 저장해 사용자가 직관적으로 이해하고 사용 가능
- 쿼리문이나 쿼리에 대한 결과도 모두 JSON
- 사전 데이터 입력시 JSON 형식으로 가공이 필요한데, Logstach에서 변환을 지원
- RESTFul API
- 멀티테넌시 (multitenancy)
- Elasticsearch 데이터는 index 라는 논리적인 집합 단위로 구성되어 서로 다른 저장소에 분산 저장
- 이 index를 별도의 커넥션 없이 하난의 질의로 묶어서 검색하고, 결과를 하나의 출력으로 도출하는 특징을 멀티테넌시라고 함
Logstash
- Logstash는 JRuby로 되어있어 자바의 런타임 머신위에서 돌아감
- 데이터 처리를 위해 입력(inputs) 필터(filters) 출력(outputs)의 과정을 거침
- 입력 : 다양한 데이터 저장소로부터 데이터를 입력받음
- 필터 : 데이터를 확장, 변경, 필터링 및 삭제 등의 처리 가공
- 출력 : 데이터 저장소로 데이터 전송
- Elasticsearch에서 데이터 색익과 동시에 로컬 파일이나 AWS S3 저장소로 동시 송출 가능
- Redis, Kafka로 천송하는 경우와 같이 독자적으로 사용되기도 함
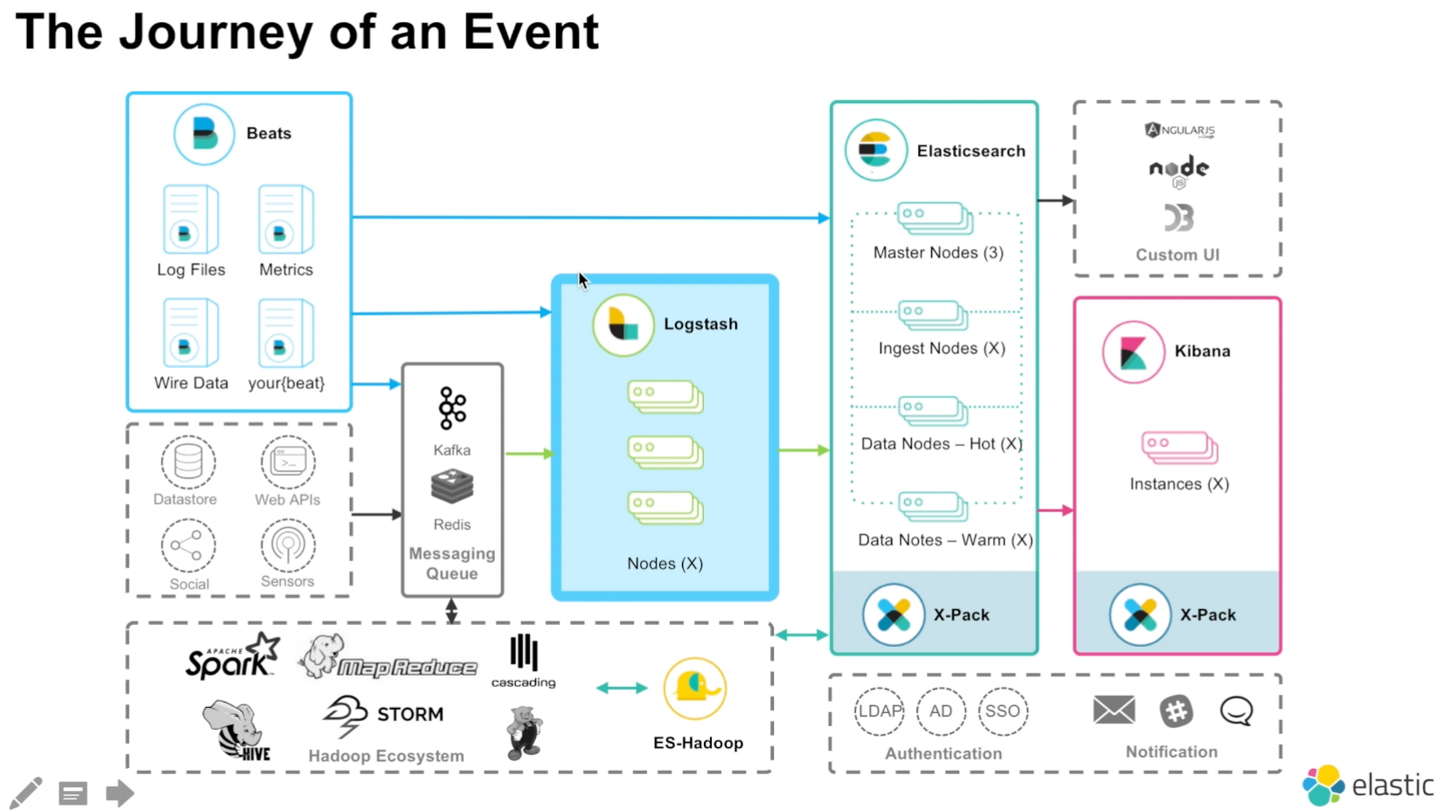
Kibana
- Elasticsearch를 가장 쉽게 시각화 할 수 있는 도구
- aggregation의 집계 기능을 이용해 문서, 집계 결과 등을 불러와 웹 도구로 시각화
- Discover, Visualize, Dashboard 3개의 기본 메뉴와 다양한 App 구성, 플러그인을 통해 App 설치 가능
- Discover : 색인된 소스 데이터들의 검색을 위한 메뉴로 검색 창에 질의문을 통해 데이터를 간편하게 검색, 필터링할 수 있고, 확인하고 싶은 필드만 선택해 테이블 형태로 조회 가능
- Visualize : aggregation 집계 기능을 통해 조회된 데이터의 통계를 다양한 차트로 표현할 수 있는 패널 메뉴
- Dashboard : Visualize 에서 만들어진 시각화 도구들을 조합해 대시보드 화면을 만들고 저장, 불러오는 역할을 하는 메뉴
728x90
'ssung_항해일지 > 항해99_실전 프로젝트' 카테고리의 다른 글
| 실전 프로젝트 - 11일차 (0) | 2023.03.20 |
|---|---|
| 실전 프로젝트 - 9일차 (0) | 2023.03.19 |
| 실전 프로젝트 - 7일차 (0) | 2023.03.16 |
| 실전 프로젝트 - 5일차 (0) | 2023.03.15 |
| 실전 프로젝트 - 4일차 (0) | 2023.03.14 |