Redshift
- AWS에서 지원하는 데이터 웨어하우스 서비스
- 2PB의 데이터까지 처리 가능
- 최소 160GB로 시작해 점진적으로 용량 증감 가능
- Still OLAP
- 응답속도가 빠르지 않기 때문에 프로덕션 데이터베이스로 사용불가
- 컬림 기반 스토리지
- 레코드 별로 저장이 아닌 컬럼 별로 저장
- 컬럼 별 압축이 가능하며 컬럼을 추가하거나 삭제하는 것이 아주 빠름
- 벌크 업데이트 지원
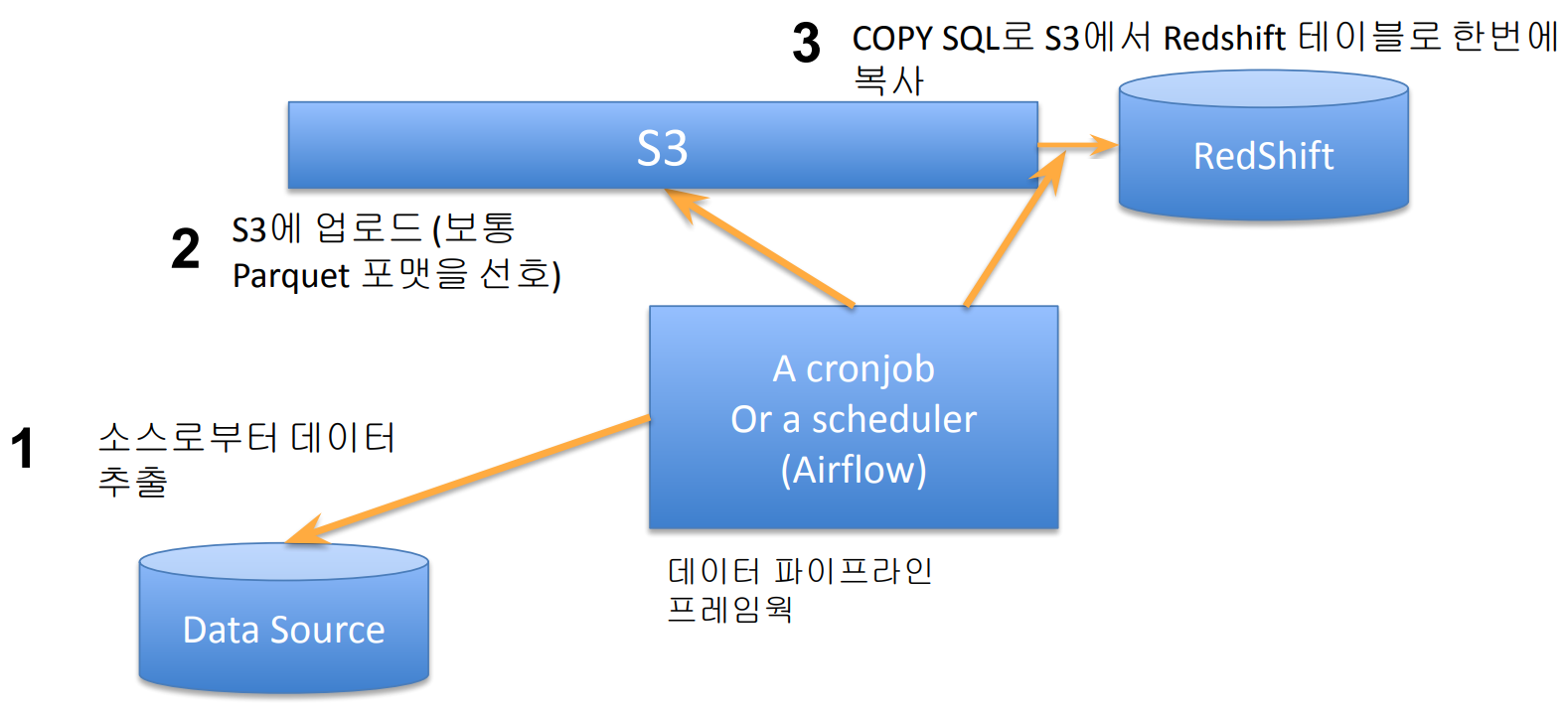
- 레코드가 들어있는 파일을 S3로 복사 후 COPY 커맨드로 Redshift로 일괄 복사
- 고정 용량/비용 SQL 엔진
- 최근 가변 비용 옵션도 제공 (Redshift Serverless)
- 데이터 공유 기능 (Datashare)
- 다른 AWS 계정과 특정 데이터 공유 가능
- 다른 데이터 웨어하우스처럼 primary key uniqueness를 보장하지 않음
- SQL 기반 관계형 데이터 베이스
- Postgresql 8.x와 SQL이 호환
- Postgresql 8.x를 지원하는 툴이나 라이브러리로 액세스 가능
Redshift 스케일링 방식
- Snowflake나 BigQuery 방식과는 다름
- 특별히 용량이 정해져있지 않고 쿼리를 처리하기 위해 사용한 리소스에 해당하는 비용 지불
- Snowflake와 BigQuery가 훨씬 더 스케일하는 데이터베이스 기술이라 볼 수 있음
- 장단점 존재 -> 비용의 예측이 불가능하다는 단점이 존재
- 특별히 용량이 정해져있지 않고 쿼리를 처리하기 위해 사용한 리소스에 해당하는 비용 지불
- Redshift에도 가변비용 옵션이 존재 -> Serverless
Redshift 저장 방식
- 두 대 이상의 노드로 구성되면, 그 시점부터 테이블 최적화가 중요
- Distkey, Diststyle, Sortkey 세 개의 키워드를 알아야 함
- Diststyle : 레코드 분배가 어떻게 이뤄지는지를 결정
- all, even, key 세 종류가 있고, even이 기본 설정 - Distkey : 레코드가 어떤 컬럼을 기준으로 배포되는지 나타냄 (Diststyle이 key인 경우)
- Sortkey : 레코드가 한 노드 내에서 어떤 컬럼을 기준으로 정렬되는지 나타냄
- 이는 보통 타임스탬프가 필드가 됨
- Diststyle : 레코드 분배가 어떻게 이뤄지는지를 결정
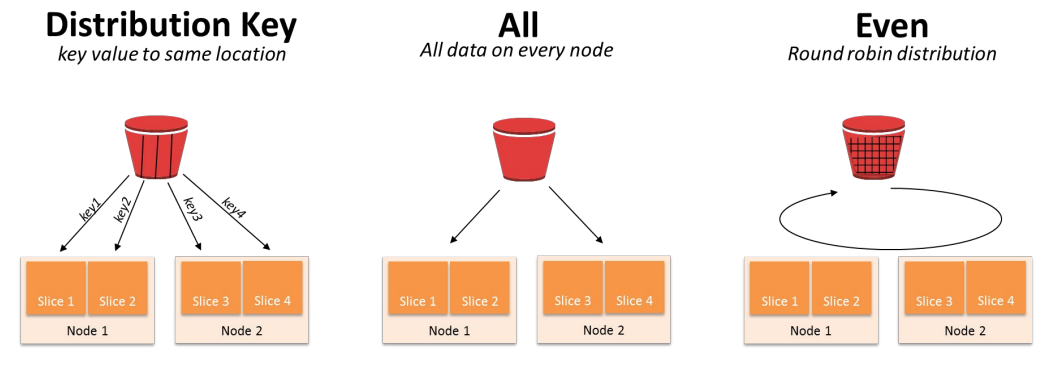
- Diststyle이 key인 경우 컬럼 선택이 잘못되면?
- 레코드 분포에 Skew가 발생 -> 분산처리의 효율성이 사라짐
- BigQuery나 Snowflake에서는 속성을 개발자가 지정할 필요가 없음 (시스템이 스스로 설정)
- 저장 방식 예
- my_table의 레코드들은 column1의 값을 기준으로 분배되고, 같은 노드(슬라이스)안에서는 column3의 값을 기준으로 정렬
CREATE TABLE my_table(
column1 INT,
column2 VARCHAR(50),
column3 TIMESTAMP,
column4 DECIMAL(18,2)
) DISTSTYLE KEY DISKEY(column1)SORTKEY(column3);Redshift 벌크 업데이트 방식 - COPY SQL
Redshift 데이터 타입
- SMALLINT (INT2)
- INTEGER (INT, INT4)
- BIGINT (INT8)
- DECIMAL (NUMERIC)
- REAL (FLOAT4)
- DOUBLE PRECISION (FLOAT8)
- BOOLEAN (BOOL)
- CHAR (CHARACTER)
- VARCHAR (CHARACTER VARYING)
- TEXT (VARCHAR(256))
- DATE
- TIMESTAMP
- GEOMETRY
- GEOGRAPHY
- HLLSKETCH
- SUPER
Redshift 초기 설정
- Schema : 다른 기타 관계형 데이터베이스와 동일한 구조
- CREATE SCHEMA raw_date; - ETL 결과가 들어감
- CREATE SCHEMA analytics; - ELT 결과가 들어감
- CREATE SCHEMA adhoc; - 테스트용 테이블이 들어감
- CREATE SCHEMA pii; - 개인정보가 들어감
- 사용자(User)생성
- CREATE USER ssung PASSWORD '...';
- select * from pg_user; - 모든 사용자를 리스트업
- 그룹 (Group)생성/설정
- 한 사용자는 다수의 그룹에 속할 수 있음
- 그룹의 문제는 계승 불가
- CREATE GROUP analytics_users; - analytics_users 그룹 생성
- CREATE GROUP analytics_authors; - analytics_authors 그룹 생성
- CREATE GROUP pii_users; - pii_users 그룹 생성
- ALTER GROUP analytics_authors ADD USER ssung; - analytics_authors그룹에 ssung 사용자 추가
- ALTER GROUP analytics_users ADD USER ssung; - a analytics_users 그룹에 ssung 사용자 추가
- ALTER GROUP pii_users ADD USER ssung; - pii_users 그룹에 ssung 사용자 추가
- 역할(Role) 생성/설정
- 역할은 그룹과 달리 계승 가능
- 역할은 사용자에게 부여될 수도 있고 다른 역할게 부여될 수도 있음
- 한 사용자는 다수의 역할에 소속 가능
- CREATE ROLE staff;
- CREATE ROLE manager;
- CREATE ROLE external;
- GRANT ROLE staff TO ssung;
- GRANT ROLE manager TO ssung;
728x90
'ssung_데이터 엔지니어링 > 7주차_데이터 웨어하우스 관리와 고급 SQL, BI 대시보드' 카테고리의 다른 글
| 데이터 웨어하우스와 고급 SQL, BI 대시보드 (5) (1) | 2023.12.01 |
|---|---|
| 데이터 웨어하우스와 고급 SQL, BI 대시보드 (4) (0) | 2023.11.30 |
| 데이터 웨어하우스와 고급 SQL, BI 대시보드 (3) (0) | 2023.11.29 |
| 데이터 웨어하우스와 고급 SQL, BI 대시보드 (1) (1) | 2023.11.27 |